Essay
Go FDE Yourself
How an agent harness achieved 35x cost & 70x speed ROI, unlocking more human value instead of layoffs.
I am an early hire at a profitable small-medium business in an old school and unsexy industry. The first exec meetings were me and the CEO on his couch. Since GPT-4o I’ve been a squeaky wheel on AI but was met with general resistance and forced to choose other higher “priority” work. This is a common pattern that I expect is playing out in small businesses everywhere right now. AI sounds nice and your first spin through Cowork and Codex shocks your CEO, but the hard part is demonstrating real ROI on your time and token spend. I wasn’t able to get any buy-in until I FDE’d myself. The Forward Deployed Engineer (FDE) is an external-facing engineer who is deployed into a customer’s business and stays until the solution ships. In this case, the customer was my own company. So I started shipping.
Looking at surface areas with heavy human-computer interaction demanding significant human hours (and cost), I focused on one of the least sexy bottlenecks imaginable. Tire catalogs for tens of thousands of SKUs arrive from hundreds of vendors, each with their own product specs that have to land in one shared format. The work is a column-by-column mapping decision with the ‘source’ data corrupted from the start. One column labeled ‘size’ actually packs three measurements into a single cell. Another labeled ‘Part Number’ is actually the UPC. And on and on across the universe of tire products. A reasoning task wearing a data entry costume.
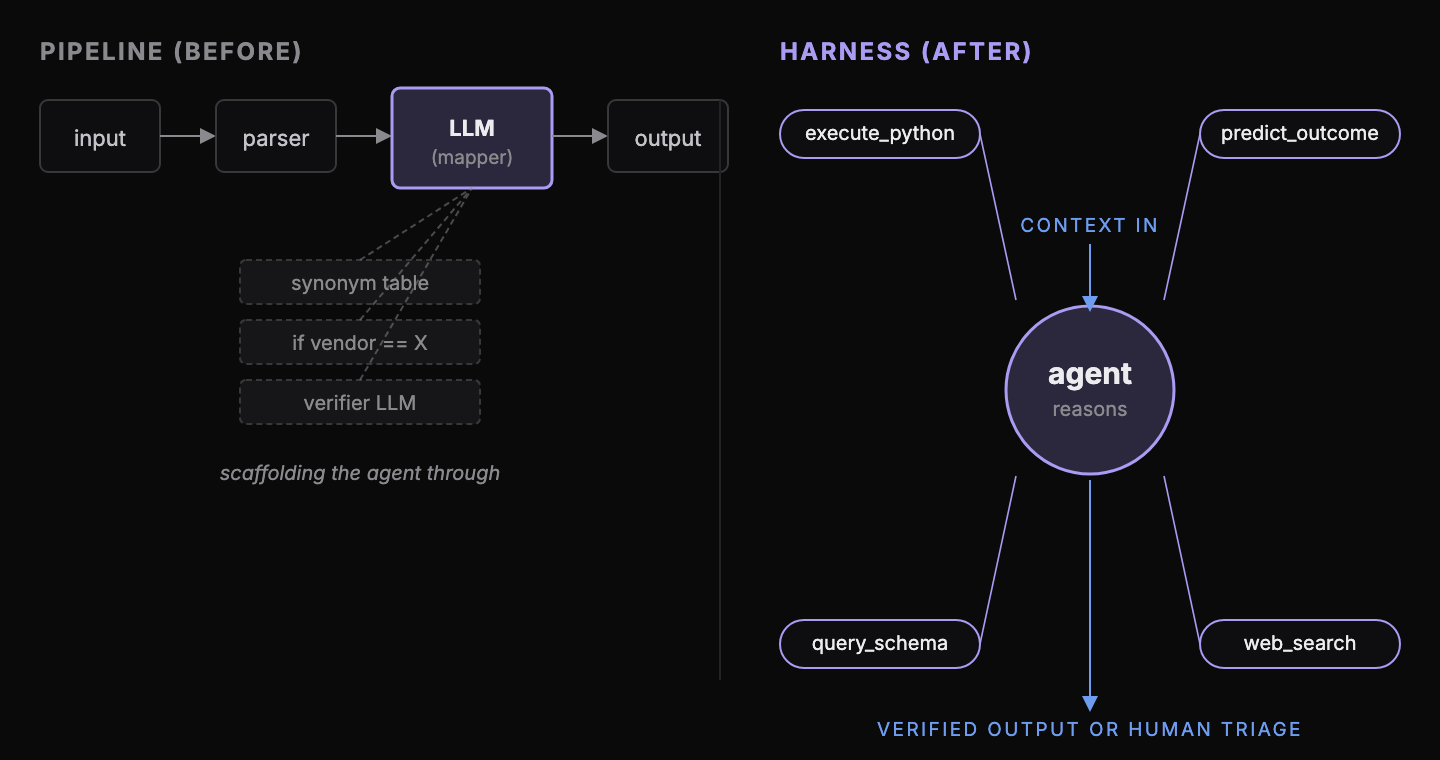
When building effective agents, the harness around the model is the product. I learned this the hard way. The harness is everything around the model: the tools the agent uses, the context it walks in with, the iteration loop it controls, and the interaction with the humans who handle the cases it flags. The model is the intelligence operating inside the harness. I started with a pipeline and an LLM bolted on at every decision. It worked for four vendors and broke on the fifth. I fixed it. It broke on the seventh. Every if vendor == X I added was an admission that the agent could not do what I was asking. It could. I was just the one in the way. You cannot patch your way to coverage on a space that is infinite. So I deleted 3,000 lines of code. And then it started working.
1. The harness in three pillars
The harness is the system and set of tools that lets the agent reason about a problem and verify its own answer. Three pillars hold it up: tools, context engineering, and an iteration loop the agent controls. Using only these three is the discipline. Resisting everything else is the work. It’s the same instinct as parenting a smart child. You give them tools to handle new situations, not a script for every one.
This is not new. @Thariq from the Claude Code team wrote in Seeing like an Agent that you must to pay attention to how the model acts, read its outputs, and shape your tools to its abilities. When the agent fails to achieve its goal, this means reading the trace from the agent’s point of view, asking what it would have needed in that moment, then giving it that tool or that context. I was particularly inspired by @badlogicgames’ approach to Pi, specifically that the agent’s tool surface should be exactly the size of the job. No helper tools that pre-decide for the agent or close the gap just for this one case.
Tools
Only the ones the job demands: execute_python to write and run code against the file, predict_outcome to test an action before committing, queryable access to the internal database schema, and web search. That’s it. Any helper that closes the gap for one case is in the way of the model’s reasoning, and was exactly what kept it from working. Each of those capabilities lives in a tool, and the tools took longer to get right than the agent. The acid test: does a tool add capability, or just get in the way?
Context engineering
The agent walks in with the database as a queryable resource, the most similar prior runs as examples, and the file’s own values as evidence. It already knows what good looks like and what it is graded on. When a run fails, the temptation from the days of prompt engineering is to make the prompt heavier. Making the prompt heavier rarely helps. The fix is almost always to design the right context. The prompt tells the agent how to read the world. The context is the agent’s world.
Iteration with verifiable feedback
The agent calls predict_outcome, reads its own expected score, and revises when the score is below threshold. There is a budget; when it runs out, the run routes to a human with the full trace. There is never a silent fallback.
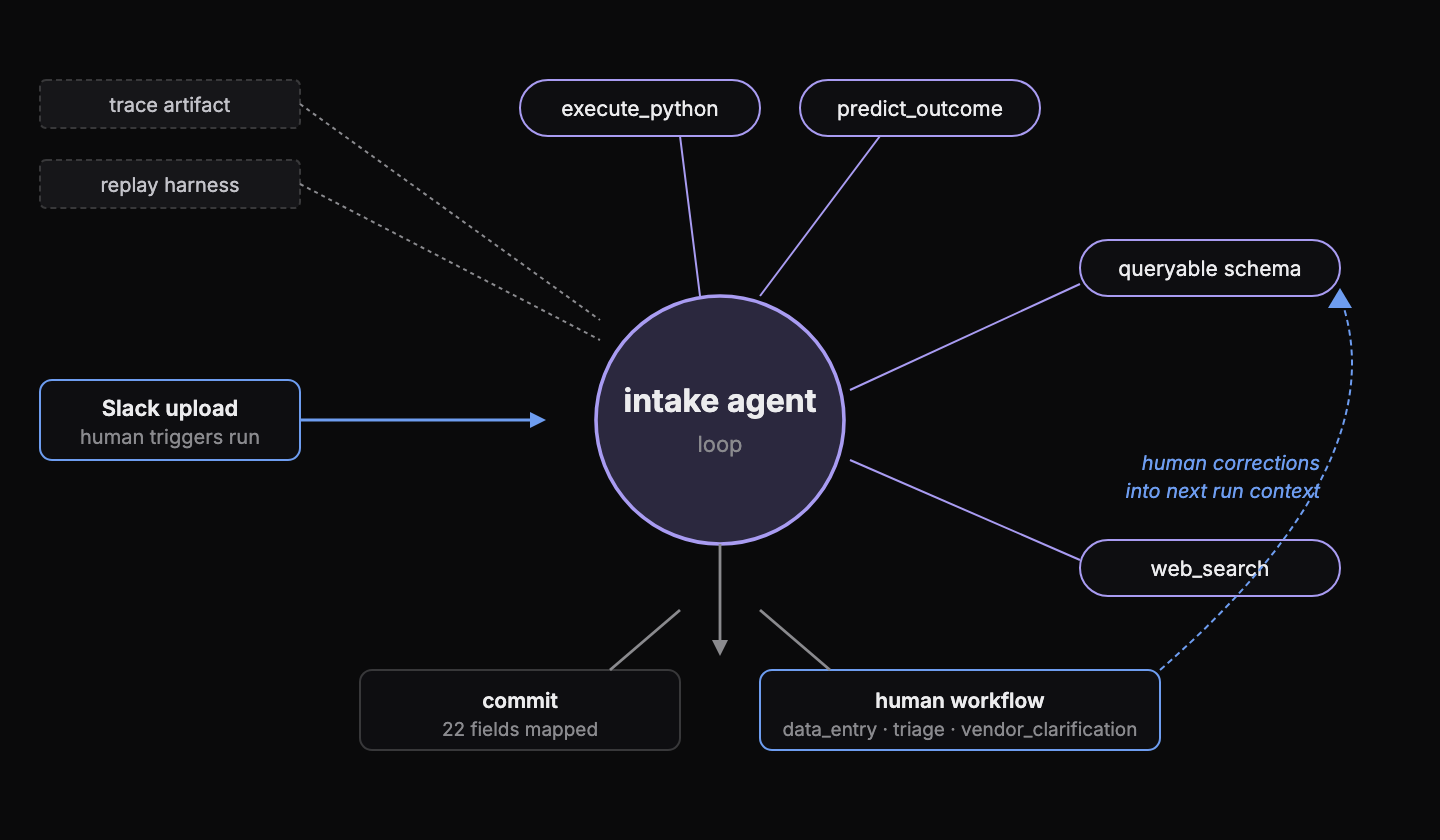
2. Architecture, named
The harness is a small set of well-scoped pieces, wired so the agent’s reasoning is the part that moves.
- Intake agent loop. Reads the file, queries the schema, proposes a column mapping, calls
predict_outcomeagainst its own proposal, and revises until the score clears threshold or the budget exhausts. execute_python. A sandboxed Python tool to inspect file bytes and run pandas against the workbook, without an LLM call per observation.predict_outcome. A self-grading tool: the agent submits a proposed action, the harness scores it against the schema and row contents, the agent revises.- Trace artifact. Every run writes the full sequence of tool calls, arguments, observations, scores, and outcome. Engineers and humans read traces the way debuggers read stack traces.
- Postflight routing. When the agent cannot converge or the predicted score is too low, the run routes to a human workflow (
data_entry,triage,vendor_clarification) with the full trace.
Two architectural notes:
- On safety:
execute_pythonis not a loose shell: it runs in a Firejail sandbox with no network access, the workbook mounted read-only, per-run scratch directories, and an audit hook that logs every call. The runner is fail-closed, so if the sandbox is unavailable it refuses to execute rather than fall back to a bare subprocess. A regulated, multi-tenant environment would need more, e.g., ephemeral isolated containers, signed inputs, and per-tenant separation. - On MCP: The agent’s tools run in-process today, and that was a deliberate choice: at this scale, latency and iteration speed matter more than independent deployment. When the same tools need to be shared across agents, or hardened and versioned on their own, the right next step is a
ToolProviderboundary first, then an MCP-style or RPC separation for the tools where isolation cost outweighs iteration cost.
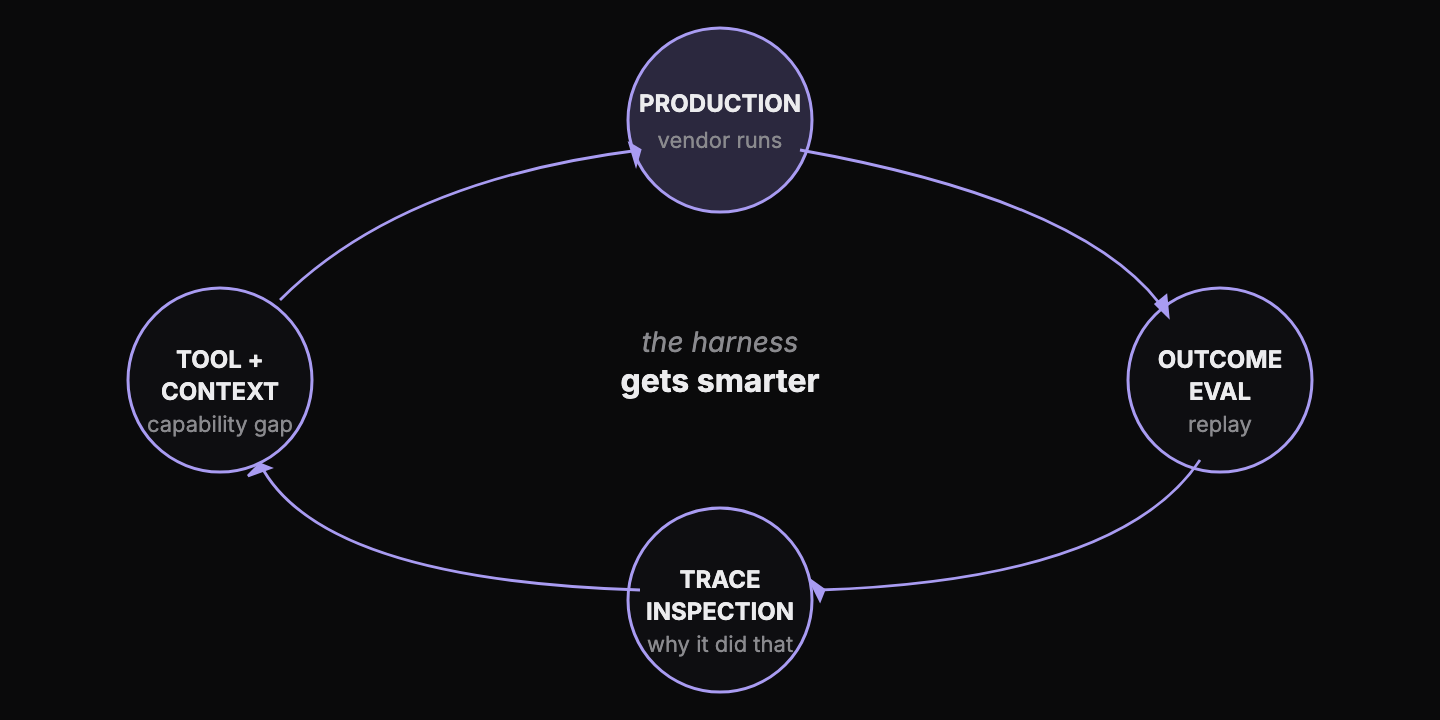
3. Eval-driven engineering
You can’t deploy an agent into production unless you can measure it. The harness is the architecture; evals and traces are its live nervous system. They are also where the next round of tool design comes from.
Any change to the agent’s reasoning replays against a curated corpus of successful production runs before merge. A run that converges differently than before gets flagged. But the production label is biased: prior-system behavior, operator tolerance, silent mistakes that never got flagged, and selection effects in how files get routed. Synthetic and adversarial fixtures (malformed sheets, schema drift, contradictory notes, missing data) run alongside it. Every run also writes a full trace: every tool call, argument, observation, revision, and the final commit or the reason it stopped. An eval is the crash report; a trace is the black box itself.
Here is a hard case: a new vendor, several required fields missing from the file. The agent has to investigate the catalog, search the web, and route the gaps it cannot close to a human. This is the full refusal-recovery-route arc, a longer run than the typical case that ships clean. Brand and part-number values are redacted.
decision: INTAKE_AGENT | turns: 31 totalexcerpt: 4 turns
turn 19 predict_outcome(sheets=[Sheet1]) → predicted_import_ready_ratio=0.0; sample_size=100 missing_canonical_fields={ ttTl: 100, mileageWarranty: 100, treadDesign: 100, rimWidthMin: 100, upcCode: 39, treadwear: 33, ... } suggested_actions=[ "ttTl 100% missing, likely a file-level constant (TL for tubeless).", "treadDesign 100% missing, call web_search on <brand> <style>", ... ]
turn 21 web_search(query="<VENDOR_BRAND> <STYLE_NAME> tread design treadwear mileage warranty passenger tire") → "Sources are thin and conflicting. Two distinct <STYLE_NAME> products surface; neither matches a standard passenger tire treadwear mileage warranty."
turn 28 propose_mapping({ sheets: [...], operator_workflow: data_entry }) → validated=False; error="primaryMfgCode_scp_required" hint="File has 2+ candidate columns for primaryMfgCode. Score them first."
turn 31 propose_mapping({ sheets: [22 columns mapped, file_level_constants={ttTl: 'TL'}], operator_workflow: data_entry }) → validated=True; intake_proposal_validated=True (commit: 22 columns mapped automatically, 1 file-level constant inferred, remaining rows route to human data_entry workflow with full trace)The agent self-grades at zero, searches the web, finds thin and conflicting sources, and acknowledges the gap instead of inventing values. It is refused once for a structured reason, then commits a validated mapping: 22 columns mapped automatically, the missing fields handed to a human with the full trace. No silent commit. No fabricated values.
Traces are also where new tools come from. On certain multi-sheet workbooks the agent would call execute_python thirty times in a row, exploring structure but never advancing to a commit. The fix was a new tool called checkpoint_nudge that interrupts after five exploratory calls and tells the agent to step back and predict. The next replay showed a previously stuck file class converge end-to-end for the first time ever. Production runs feed evals, evals fail loudly when something drifts, traces explain why, and a new tool closes the gap.
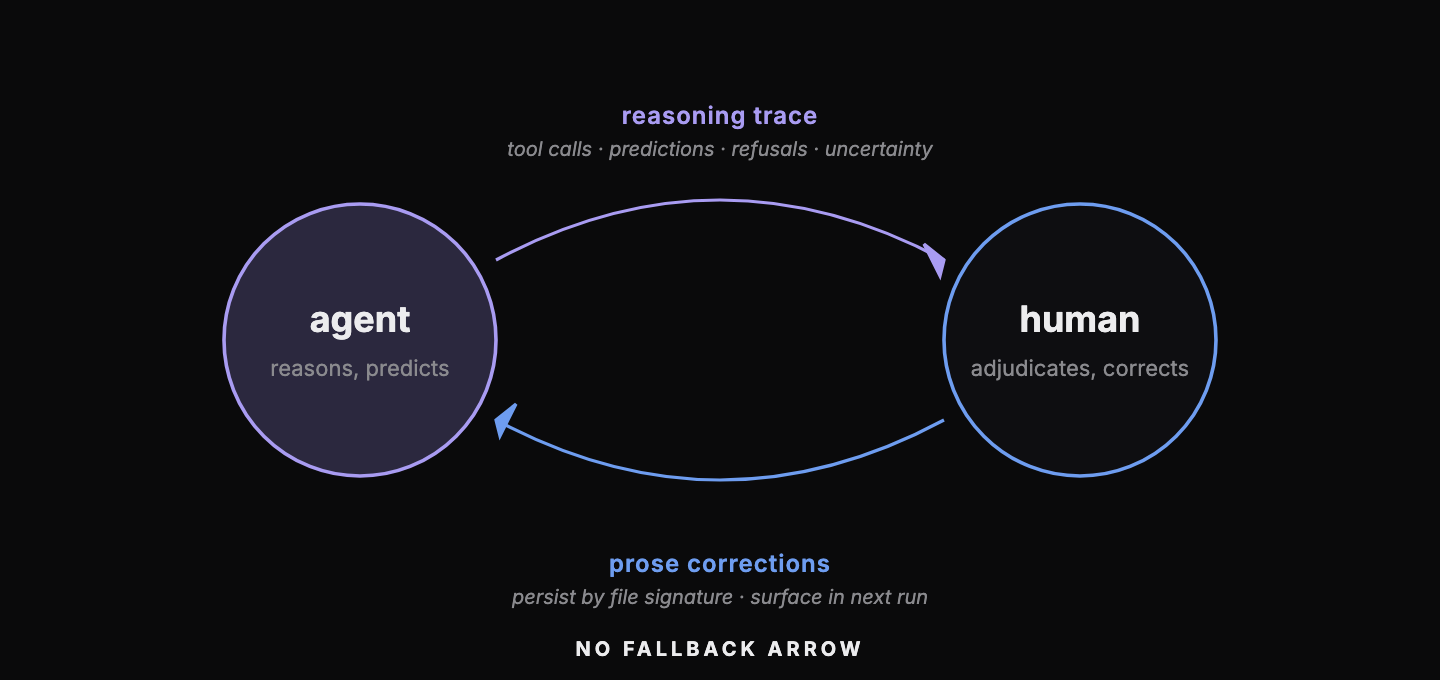
4. Human-in-the-loop
The space between the agent and the human is an important design surface. The default move for many is to wire this as a fallback: if the AI fails, route to a human. The result is a deployment humans distrust and ignore. The agent here treats the human as a partner whose context it imports.
The FDE’s real customer is the person doing the work. The work that returns ROI is the unsexy stack underneath, including process mapping, data plumbing, and change management. If the operator does not trust the deployment, it goes unused no matter how much it cost to build. That trust has a script. The deployment doesn’t say “stop working, the AI handles it now.” It says “the AI handles the obvious rows, you handle the flagged ones, and your corrections become its memory.”
When the agent cannot converge, it raises its hand, and the human gets the full reasoning trace: every tool call, every prediction, every revision, and why it stopped. The human writes back a plain-English note that persists by file signature and surfaces the next time a similar file walks in. Today those notes are scoped by file signature; at scale the right design is a normalized correction ledger with vector retrieval over it. This transparency builds trust: the human sees when the agent is confident and when it is guessing; the agent sees what the human overrode, and why. The human’s institutional knowledge becomes the agent’s context.
Change management must be a key part of the architecture if the deployment is going to work.
5. How ROI shows up
The numbers reduce to labor hours. A workload that consumed a team of 5 for ~105 hours now runs in about 1 hour of agent compute plus 30 minutes of human review: roughly 525 person-hours per workload returned to the team, at the same headcount. What I am counting is the human time before and after, with inference as the ongoing cost (the one-time engineering build is excluded). The freed hours are going to higher-leverage work, like the vendor relationships and catalog hygiene that nobody had bandwidth for. The agent is giving us leverage that was gated behind two weeks per workload as the cost of entry.
The default ROI math puts dollars saved on headcount over AI spend, judges the deployment on whether anyone got fired, finds that nobody did, and concludes there was no return. The right ratio is throughput per dollar: post-deployment output over AI spend. Token volume is the right metric for the infrastructure layer, where serving capacity is the business. At the deployment layer it is an input dressed up as an output, the way “lines of code per engineer” was in the 1990s. A company can serve trillions of tokens and produce no operational leverage at all.
One honest caveat. The operator trust I leaned on was earned over years of internal context, not the cold start an external FDE faces walking into someone else’s company. What I stake the transferable claim on is the discipline, the harness, the evals, and the human-in-the-loop design. The trust has to be re-earned every time.
6. What worked
Go deep first. Spend real time with the humans before any code. You must be able to describe their task in detail in your own words before you build. Skip that and you will ship a demo, call it ROI, and quietly move on.
Tools beat rules. Every rule that hides a judgment call in production code is a missing capability. When the agent fails, build the tool it would have used. A script for every situation kills the agent’s ability to handle new ones.
Context engineering beats prompt engineering. When the prompt is not getting the right answer, the fix is rarely more prompt. Give the agent the context it was missing.
Verifiability beats confidence. Build the grading tool first. Without it, an agent that sounds confident ships errors silently. With it, the agent knows when to commit and when to raise its hand.
Traces are where tools come from. Production traces tell you which capabilities the agent is missing. Intuition guesses; traces measure. An agent without a trace is one you can’t improve.